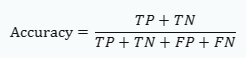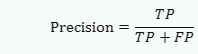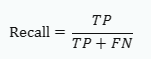2022년 제 23회 정보시스템 감리사 데이터베이스 기출문제 풀이 71-75번까지 풀이를 진행하겠습니다. 도움이 되시길 바랍니다.
데이터베이스
문제 71
71. 다음은 정보 검색, 텍스트 마이닝에서 문서 집합과 용어에 대한 TFIDF의 개념을 설명한다. 만일, 문서 집합 D에 다음과 같이 d1, d2의 두 문서만 존재한다고 할 때, 용어 “this”에 대한 TFIDF 값이 옳은 것은?
- TF는 term frequency의 약어로, 해당 용어가 주어진 문서에 얼마나 많이 나타나는지를 나타낸다. - IDF는 nvers document frequency의 약어로, 해당 용어가 문서 집합에 얼마나 많이 나타나는지에 대한 역수를 나타낸다. - TFIDF는 문서 집합에서 특정 단어가 주어진 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치이다.
TF-IDF (Term Frequency-Inverse Document Frequency)의 개념을 이해하고 계산할 수 있는지를 테스트하는 것입니다. TF-IDF는 정보 검색과 텍스트 마이닝에서 중요한 개념으로, ;문서 집합에서 특정 단어가 주어진 문서 내에서 얼마나 중요한지를 나타내는 통계적 수치입니다.
각 문항에 대한 설명
TF-IDF는 TF와 IDF의 곱으로 계산됩니다. TF (Term Frequency)는 특정 단어가 문서 내에서 얼마나 자주 등장하는지를 나타내며, IDF (Inverse Document Frequency)는 특정 단어가 문서 집합 전체에서 얼마나 흔하게 등장하는지의 역수를 나타냅니다.
즉, IDF는 흔한 단어에 대해 패널티를 주는 역할을 합니다.
문서 d1과 d2에서 "this"에 대한 TF-IDF를 계산해 보겠습니다. - 문서 d1에서 "this"의 TF는 1/5 = 0.2입니다. (문서 d1에는 총 5개의 단어가 있습니다) - 문서 d2에서 "this"의 TF는 2/5 = 0.4입니다. (문서 d2에는 총 5개의 단어가 있습니다)
문서 집합 D에서 "this"의 IDF는 log(2/2) = 0입니다. (문서 집합 D에는 총 2개의 문서가 있으며, "this"는 모든 문서에서 등장합니다)
따라서, 정답은 ① TFIDF(“this”, d1, D) = 0, TFIDF(“this”, d2, D) = 0입니다. 이 문제는 TF-IDF의 계산 방법을 이해하고, 특히 IDF가 어떻게 흔한 단어에 대한 페널티를 부여하는지를 이해하는 데 중점을 두고 있습니다. 이 경우, "this"는 모든 문서에서 등장하기 때문에 그 중요도가 0으로 판단됩니다. 이는 TF-IDF가 특정 문서 내에서만 자주 등장하고 다른 문서에서는 잘 등장하지 않는 단어를 찾는 데 유용하다는 것을 보여줍니다. 이러한 단어들은 그 문서의 주제를 잘 나타낼 가능성이 높습니다.
문제 72
72. 다음 설명 중에서 NoSQL의 특징이나 장점과 가장 거리가 먼 것은?
① NoSQL 시스템은 노드 추가를 통해 저장 공간과 처리 능력을 증가시킬 수 있어 높은 확장성을 제공한다. ② NoSQL 시스템은 데이터를 여러 노드에 복제하여 저장함으로써 고장 허용(fault tolerance) 기능을 제공한다. ③ NoSQL 시스템은 파일 레코드에 대한 샤딩 (sharding)을 사용하여 부하분산을 이룬다. ④ NoSQL 시스템은 데이터를 여러 노드에 복제 저장 함으로써 읽기(조회)와 쓰기(갱신) 성능을 개선한 다.
출제의도
NoSQL 시스템의 특징과 장점에 대한 이해를 테스트하는 것입니다. NoSQL 시스템은 관계형 데이터베이스 시스템과 달리, 확장성, 고장 허용성, 샤딩, 그리고 읽기와 쓰기 성능의 개선 등 다양한 장점을 제공합니다.
각 문항에 대한 설명
① NoSQL 시스템은 노드 추가를 통해 저장 공간과 처리 능력을 증가시킬 수 있어 높은 확장성을 제공한다. 이는 NoSQL의 주요 장점 중 하나로, 노드를 추가함으로써 시스템의 저장 공간과 처리 능력을 쉽게 확장할 수 있습니다.
② NoSQL 시스템은 데이터를 여러 노드에 복제하여 저장함으로써 고장 허용(fault tolerance) 기능을 제공한다. 이는 NoSQL 시스템이 데이터를 여러 노드에 복제하여 저장함으로써, 한 노드가 고장 나더라도 데이터 손실 없이 시스템이 계속 작동할 수 있게 하는 기능입니다.
③ NoSQL 시스템은 파일 레코드에 대한 샤딩 (sharding)을 사용하여 부하분산을 이룬다. 샤딩은 데이터를 여러 노드에 분산 저장함으로써, 각 노드가 처리해야 할 데이터의 양을 줄이고, 따라서 시스템의 전반적인 성능을 향상시키는 기법입니다.
④ NoSQL 시스템은 데이터를 여러 노드에 복제 저장 함으로써 읽기(조회)와 쓰기(갱신) 성능을 개선한다. 이는 일반적으로 참이지만, 모든 경우에 해당되는 것은 아닙니다. 데이터를 여러 노드에 복제 저장하면 읽기 성능은 향상되지만, 쓰기 성능은 반드시 향상되지는 않습니다. 왜냐하면 모든 복제본을 갱신해야 하기 때문에 쓰기 작업이 더 복잡해지고 시간이 더 걸릴 수 있기 때문입니다.
따라서, NoSQL의 특징이나 장점과 가장 거리가 먼 것은 ④입니다.
문제 73
73. 다음 표의 거래 정보에 대해서 최소지지도 (minsup)를 0.5로 하여 Apriori 알고리즘을 적용하고자 할 때, 빈발 2-항목집합(frequent 2-itemset) 모두를 옳게 나열한 것은? ① {A,B}, {A,E}, {B,E} ② {A,F}, {B,F}, {E,F} ③ {A,F}, {A,B}, {A,E}, {B,F}, {E,F}, {B,E} ④ {A,B}, {A,C}, {A,D}, {E,F}, {E,G}, {F,G}
출제의도
Apriori 알고리즘은 빈발 항목 집합을 찾는 데 사용되는 알고리즘입니다. 여기서 빈발 항목 집합이란, 데이터베이스의 거래에서 발생하는 비율(지지도)이 특정 임계값(최소 지지도) 이상인 항목 집합을 말합니다. 이 문제에서는 최소 지지도가 ;0.5로 설정되어 있으므로, 항목 집합이 거래의 50% 이상에서 발생해야 합니다.
각 문항에 대한 설명
① {A,B}, {A,E}, {B,E} {A,B}는 4번, {A,E}는 5번, {B,E}는 3번 거래에서 발생합니다. 따라서 이들의 지지도는 각각 0.4, 0.5, 0.3입니다. {A,B}와 {A,E}가 지지도가 0.5 이상입니다.
② {A,F}, {B,F}, {E,F} {A,F}는 3번, {B,F}는 2번, {E,F}는 3번 거래에서 발생합니다. 따라서 이들의 지지도는 각각 0.3, 0.2, 0.3입니다. 이들 중 어느 것도 지지도가 0.5 이상이 아닙니다.
③ {A,F}, {A,B}, {A,E}, {B,F}, {E,F}, {B,E} 이 옵션은 ①과 ②의 항목을 모두 포함하고 있습니다. 앞서 설명한 바와 같이 이들 중 {A,B}와 {A,E}만이 지지도가 0.5 이상입니다.
④ {A,B}, {A,C}, {A,D}, {E,F}, {E,G}, {F,G} {A,B}는 4번, {A,C}는 2번, {A,D}는 2번, {E,F}는 3번, {E,G}는 2번, {F,G}는 1번 거래에서 발생합니다. 따라서 이들의 지지도는 각각 0.4, 0.2, 0.2, 0.3, 0.2, 0.1입니다. 이들 중 어느 것도 지지도가 0.5 이상이 아닙니다.
따라서, 빈발 2-항목집합(frequent 2-itemset)을 옳게 나열한 것은 ① {A,B}, {A,E}입니다. 이 문제는 Apriori 알고리즘의 원리를 이해하고, 지지도를 계산하여 빈발 항목 집합을 찾는 능력을 테스트합니다. 이 경우, 주어진 데이터에서 지지도가 0.5 이상인 2-항목집합은 {A,B}와 {A,E}입니다. 이는 A와 B, 그리고 A와 E가 함께 구매될 가능성이 높음을 나타냅니다.
이 정보는 마케팅 전략을 수립하는 데 유용할 수 있습니다. 예를 들어, A와 B, 그리고 A와 E를 함께 판매하거나, 한 제품을 구매한 고객에게 다른 제품을 추천하는 등의 전략을 수립할 수 있습니다.
문제 74
74. 다음은 스팸(Spam) 메일을 인식하기 위해 구축한 예측모델로부터 얻어진 혼돈행렬(confusion matrix)이다. 이 혼돈행렬로부터 구할 수 있는 성능척도 값이 옳지 않은 것은?
① 정밀도(precision) = 45/50 ② 재현율(recall) =45/65 ③ 특이도(specificity) = 20/50 ④ 정확도(accuracy) = 75/100
출제의도
혼돈행렬(confusion matrix) 구하는 공식을 알고 있으면 간단하게 풀 수 있는 문제입니다.
혼동 행렬(confusion matrix)은 이진 분류 문제의 성능을 평가하는 데 사용되는 표입니다. 이 표는 모델이 예측한 클래스와 실제 클래스를 비교하여 작성됩니다.
혼동 행렬의 각 요소는 다음과 같습니다: 1. True Positive (TP): 모델이 양성 클래스를 양성으로 올바르게 예측한 경우 2. True Negative (TN): 모델이 음성 클래스를 음성으로 올바르게 예측한 경우 3. False Positive (FP): 모델이 음성 클래스를 양성으로 잘못 예측한 경우 4. False Negative (FN): 모델이 양성 클래스를 음성으로 잘못 예측한 경우 이 혼동 행렬을 바탕으로 다음과 같은 성능 척도를 계산할 수 있습니다:
각 문항에 대한 설명
이 혼동 행렬을 바탕으로 다음과 같은 성능 척도를 계산할 수 있습니다: 1. 정확도(Accuracy): 모델이 올바르게 예측한 샘플의 비율 2. 정밀도(Precision): 양성으로 예측된 샘플 중 실제로 양성인 샘플의 비율
3. 재현율(Recall) 또는 민감도(Sensitivity): 실제 양성 샘플 중 모델이 양성으로 예측한 샘플의 비율 4. 특이도(Specificity): 실제 음성 샘플 중 모델이 음성으로 예측한 샘플의 비율
5. F1 점수(F1 Score): 정밀도와 재현율의 조화 평균
이 문제에서 주어진 혼동 행렬의 값은 TP=45, FN=20, FP=5, TN=30입니다.
각 성능 척도를 계산하면 다음과 같습니다: ① 정밀도(precision) = 45/50 = TP/(TP+FP) = 45/(45+5) = 0.9 ② 재현율(recall) = 45/65 = TP/(TP+FN) = 45/(45+20) = 0.69 ③ 특이도(specificity) = 20/50 = TN/(TN+FP) = 30/(30+5) = 0.86 ④ 정확도(accuracy) = 75/100 = (TP+TN)/(TP+TN+FP+FN) = (45+30)/(45+30+5+20) = 0.75
따라서, 성능 척도 값을 옳지 않게 계산한 것은 ③ 특이도(specificity)입니다.
예를 들어, 정밀도와 재현율은 모델이 양성 클래스를 얼마나 잘 예측하는지를 측정하며, 특이도는 모델이 음성 클래스를 얼마나 잘 예측하는지를 측정합니다. F1 점수는 정밀도와 재현율을 모두 고려한 척도로, 두 척도 사이의 균형을 나타냅니다.
문제 75
75. 다음은 분산 데이터베이스에서의 투명성(transparency) 에 대한 설명이다. 다음 투명성에 대한 설명 중에서 가장 적절하지 않은 것은?
① 이름부여 투명성(naming transparency)은 분산 데이터베이스가 어떻게 설계되는지와 어느 사이트에서 트랜잭션이 실행되는지를 사용자에게 가려주는 것을 의미한다. ② 분산 투명성(distribution transparency) 또는 네트워크 투명성(network transparency)은 사용자에게 네트워크의 세부 사항과 분산 시스템 내에서 데이터 저장 장소의 위치를 가려주는 것을 의미한다. ③ 위치 투명성(location transparency)은 어떤 작업을 수행하기 위해 사용된 명령은 데이터의 위치와 명령이 입력된 시스템의 위치와 무관해야 함을 의미한다. ④ 중복 투명성(replication transparency)은 높은 가용성, 성능, 신뢰도를 위해 데이터 사본들이 여러 사이트에 중복될 수 있음을 의미하며, 중복된 사본의 존재를 사용자에게 가려준다.
출제의도
이 질문은 분산 데이터베이스에서의 투명성에 대한 이해를 테스트하려는 것입니다. 투명성은 사용자가 분산 데이터베이스의 복잡성을 인식하지 못하게 하는 속성입니다.
각 문항에 대한 설명
① 이름부여 투명성(naming transparency)은 분산 데이터베이스가 어떻게 설계되는지와 어느 사이트에서 트랜잭션이 실행되는지를 사용자에게 가려주는 것을 의미한다. 이름부여 투명성은 사용자가 데이터 항목의 이름만으로 데이터에 액세스 할 수 있게 해주는 속성입니다. 그러나 이 설명은 이름부여 투명성의 정의와 일치하지 않습니다. 이름부여 투명성은 데이터베이스의 설계나 트랜잭션이 실행되는 위치를 가리는 것이 아니라, 데이터 항목의 위치와 무관하게 동일한 이름을 사용하여 데이터 항목에 액세스할 수 있게 해 줍니다.
② 분산 투명성(distribution transparency) 또는 네트워크 투명성(network transparency)은 사용자에게 네트워크의 세부 사항과 분산 시스템 내에서 데이터 저장 장소의 위치를 가려주는 것을 의미한다. 이 설명은 분산 투명성의 정의와 일치합니다. 분산 투명성은 데이터가 네트워크의 어느 위치에 있는지 사용자에게 가려주는 속성입니다.
③ 위치 투명성(location transparency)은 어떤 작업을 수행하기 위해 사용된 명령은 데이터의 위치와 명령이 입력된 시스템의 위치와 무관해야 함을 의미한다. 이 설명은 위치 투명성의 정의와 일치합니다. 위치 투명성은 데이터의 물리적 위치와 무관하게 데이터에 액세스 할 수 있게 해주는 속성입니다.
④ 중복 투명성(replication transparency)은 높은 가용성, 성능, 신뢰도를 위해 데이터 사본들이 여러 사이트에 중복될 수 있음을 의미하며, 중복된 사본의 존재를 사용자에게 가려준다. 이 설명은 중복 투명성의 정의와 일치합니다. 중복 투명성은 데이터의 복제본이 여러 위치에 존재할 수 있지만, 사용자는 하나의 데이터 항목처럼 보이게 해주는 속성입니다.
따라서, 가장 적절하지 않은 설명은 ① 이름부여 투명성(naming transparency)입니다. 이 문제는 분산 데이터베이스의 투명성 개념을 이해하고, 각 투명성이 무엇을 의미하는지를 정확하게 파악하는 능력을 테스트합니다.
오늘까지 데이터베이스 기출문제 풀이를 모두 풀어 보았습니다. 다음 시간에는 소프트웨어 공학 기출문제 풀이 26-30번까지 풀이를 진행해 보겠습니다. 오늘도 읽어 주셔서 감사합니다.