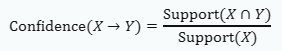2022년 제 23회 정보시스템 감리사 데이터베이스 기출문제 풀이 66-70번까지 풀이를 진행하겠습니다. 도움이 되시길 바랍니다.
데이터베이스
문제 66
66. 다음은 데이터베이스 회복(recovery) 기법의 지연 갱신(deferred update)과 즉시 갱신 (immediate update)에 대한 설명이다. 다음 설명 중에서 옳은 것을 모두 고른 것은?
가.지연 갱신에서는 완료(commit) 이전에 실패한 트랜잭션의 경우 UNDO가 필요하지않다. 나 즉시 갱신은 완료 이후 UNDO와 REDO가 필요하지 않기 때문에 NO-UNDO/NO-REDO 알고리즘으로 알려져 있다. 다. 즉시 갱신에서는 완료 이전에 실패한 트랜잭션의 경우 UNDO를 수행해야한다. 라. 지연 갱신에서는 완료된 트랜잭션에 대해서도 로그를 사용하여 REDO를 수행해야 할 수 있다.
① 다, 라 ② 나, 라 ③ 나, 다, 라 ④ 가, 다, 라
출제의도
데이터베이스 회복기법중 지연 갱신(deferred update)과 즉시 갱신(immediate update)에 대한 이해를 확인하는 것입니다.
각 문항에 대한 설명
가. 지연 갱신에서는 완료(commit) 이전에 실패한 트랜잭션의 경우 UNDO가 필요하지 않다. 이 설명은 옳습니다. 지연 갱신 방식에서는 트랜잭션의 커밋이 완료될 때까지 데이터베이스에 기록을 지연하므로, 중간에 장애가 발생하더라도 데이터베이스에 기록되지 않았으므로 UNDO가 필요 없습니다.
나. 즉시 갱신은 완료 이후 UNDO와 REDO가 필요하지 않기 때문에 NO-UNDO/NO-REDO 알고리즘으로 알려져 있다. 이 설명은 틀립니다. 즉시 갱신 방식에서는 데이터 변경 시 로그와 데이터베이스에 즉시 갱신하므로, 커밋되기 전에 장애가 발생하면 UNDO를, 커밋 후에 장애가 발생하면 REDO를 수행해야 합니다.
다. 즉시 갱신에서는 완료 이전에 실패한 트랜잭션의 경우 UNDO를 수행해야 한다.이 설명은 옳습니다. 즉시 갱신 방식에서는 트랜잭션 수행 도중 데이터를 변경하면 변경 정보를 로그 파일에 저장하고, 트랜잭션이 부분 완료되기 전이라도 모든 변경 내용을 즉시 데이터베이스에 반영하므로, 완료 이전에 실패한 트랜잭션의 경우 UNDO를 수행해야 합니다.
라. 지연 갱신에서는 완료된 트랜잭션에 대해서도 로그를 사용하여 REDO를 수행해야 할 수 있다. 이 설명은 옳습니다. 지연 갱신 방식에서는 트랜잭션의 커밋이 완료될 때까지 데이터베이스에 기록을 지연하므로, 완료된 트랜잭션에 대해서도 로그를 사용하여 REDO를 수행해야 할 수 있습니다.
따라서, 옳은 항목을 모두 고른 것은 ④ 가, 다, 라입니다. 이러한 이해는 데이터베이스 시스템의 안정성과 신뢰성을 보장하는 데 중요한 역할을 합니다
문제 67
67. 다음의 구매 데이터로부터 연관규칙 Apriori 알고 리즘을 통해 도출할 수 있는 연관규칙 중에서 신 뢰도(confidence) 값이 가장 큰 것은?
① A B ② A C ③ B A ④ B C
출제의도
Apriori 알고리즘을 이용한 연관규칙 분석에서 신뢰도(confidence)에 대한 이해를 확인하는 것입니다.
신뢰도는 아래와 같이 계산됩니다
신뢰도 계산식
여기서 Support(X)는 아이템 X가 포함된 거래의 수, Support(X ∩ Y)는 아이템 X와 Y가 동시에 포함된 거래의 수를 나타냅니다
각 문항에 대한 설명
① A → B: 아이템 A를 구매한 고객 중 아이템 B도 구매한 고객의 비율입니다.
② A → C: 아이템 A를 구매한 고객 중 아이템 C도 구매한 고객의 비율입니다.
③ B → A: 아이템 B를 구매한 고객 중 아이템 A도 구매한 고객의 비율입니다.
④ B → C: 아이템 B를 구매한 고객 중 아이템 C도 구매한 고객의 비율입니다.
* 이제 각 항목의 신뢰도를 계산해보겠습니다:
① A → B: A를 구매한 고객은 1, 2, 3, 5번이며, 이 중 B를 구매한 고객은 1, 3번입니다. 따라서 신뢰도는 2/4 = 0.5입니다.
② A → C: A를 구매한 고객은 1, 2, 3, 5번이며, 이 중 C를 구매한 고객은 1, 5번입니다. 따라서 신뢰도는 2/4 = 0.5입니다.
③ B → A: B를 구매한 고객은 1, 3, 4번이며, 이 중 A를 구매한 고객은 1, 3번입니다. 따라서 신뢰도는 2/3 ≈ 0.67입니다.
④ B → C: B를 구매한 고객은 1, 3, 4번이며, 이 중 C를 구매한 고객은 1번입니다. 따라서 신뢰도는 1/3 ≈ 0.33입니다.
따라서, 신뢰도가 가장 큰 연관규칙은 ③ B → A입니다. 이는 아이템 B를 구매한 고객 중 아이템 A도 구매할 확률이 가장 높다는 것을 의미합니다. 이러한 이해는 마케팅 전략 수립 등에 유용하게 사용될 수 있습니다
문제 68
68. 뷰(view)는 기본 릴레이션이나 이미 정의된 뷰를 사용하여 정의된다. 아래 그림은 뷰의 갱신가능성의 수준에 따른 뷰들의 유형 간 포함 관계를 도식화한 것이다.
갱신 가능성을 기준으로 볼 때 (ㄱ), (ㄴ), (ㄷ)에 각각 (가), (나), (다)의 내용을 가장 가깝게 연결한 것은?
(가) 사용자가 정의할 수 있는 모든 뷰 ; (나) 상용 관계 DBMS들이 갱신을 허용하는 뷰 ; (다) 이론적으로 갱신이 가능한 뷰
① (ㄱ)과 (가), (ㄴ)과 (다), (ㄷ)과 (나) ② (ㄱ)과 (다), (ㄴ)과 (가), (ㄷ)과 (나) ③ (ㄱ)과 (나), (ㄴ)과 (다), (ㄷ)과 (가) ④ (ㄱ)과 (가), (ㄴ)과 (나), (ㄷ)과 (다)
출제의도
이 문제는 다시 공부해서 업데이트 하겠습니다.
각 문항에 대한 설명
정답은 ① (ㄱ)과 (가), (ㄴ)과 (다), (ㄷ)과 (나) 입니다.
문제 69
69. 데이터 웨어하우스가 일반 데이터베이스와 다른 특징에 대한 설명 중 옳지 않은 것은?
① 주제 지향적(subject-oriented) 내용 : 일반 데이 터베이스가 업무 처리 중심의 데이터로 구성된 반면 데이터 웨어하우스는 의사 결정이 필요한 주제를 중심으로 데이터를 구성한다.
② 통합된(integrated) 내용 : 데이터 웨어하우스는 여러 데이터베이스에서 필요한 데이터를 추출하여 의사 결정에 필요한 분석 및 비교 작업을 지원한다.
③ 시간에 따라 변화하지 않는(time-invariant) 내용 : 일반 데이터베이스는 현재와 과거 데이터를 함께 유지하지만 데이터 웨어하우스는 현재 시점의 데이터만을 유지한다.
④ 비소멸성(nonvolatile) 내용 : 일반 데이터베이스에 저장된 데이터는 삽입, 삭제, 갱신 연산이 자주 발생하지만 데이터 웨어하우스는 검색 작업만 수행되는 읽기 전용의 데이터를 유지한다.
출제의도
데이터웨어하우스와 일반 데이터베이스의 차이점에 대한 이해를 확인하는 것입니다.
각 문항에 대한 설명
① 주제 지향적(subject-oriented) 내용: 이 설명은 옳습니다. 데이터 웨어하우스는 주제 중심의 데이터 모음으로, 의사 결정에 필요한 주제를 중심으로 데이터를 구성합니다. 반면, 일반 데이터베이스는 업무 처리 중심의 데이터로 구성됩니다.
② 통합된(integrated) 내용: 이 설명은 옳습니다. 데이터 웨어하우스는 여러 데이터베이스에서 필요한 데이터를 추출하여 의사 결정에 필요한 분석 및 비교 작업을 지원합니다.
③ 시간에 따라 변화하지 않는(time-invariant) 내용: 이 설명은 틀립니다. 데이터 웨어하우스는 현재뿐만 아니라 과거의 데이터도 유지합니다. 이는 보고 및 분석 목적으로 설계되었기 때문입니다. 반면, 일반 데이터베이스에는 주로 최신 정보만 포함되어 있습니다.
④ 비소멸성(nonvolatile) 내용: 이 설명은 옳습니다. 일반 데이터베이스에 저장된 데이터는 삽입, 삭제, 갱신 연산이 자주 발생하지만, 데이터 웨어하우스는 검색 작업만 수행되는 읽기 전용의 데이터를 유지합니다.
따라서, 옳지 않은 설명은 ③ 시간에 따라 변화하지 않는(time-invariant) 내용입니다.
문제 70
70. 의사결정트리(decision tree) 구축 과정에서 어떤 노드 N에 클래스 0인 레코드가 1개, 클래스 1인 레코드가 5개 해당한다고 하자. 이 노드에 대한 불순도(impurity)를 표현하는 Gini 값으로 가장 적절한 것은?
① 0.0 ② 0.278 ③ 0.5 ④ 0.650
출제의도
의사결정트리에서 노드의 불순도를 측정하는 Gini 값에 대한 이해를 확인하는 것입니다. Gini 불순도는 클래스 분포의 불순도를 측정하는 지표로, 한 노드가 순수할수록(즉, 한 클래스의 샘플만을 포함할수록) Gini 불순도는 0에 가까워집니다. 반대로, 노드가 여러 클래스의 샘플을 고르게 포함하고 있을 경우, Gini 불순도는 1에 가까워집니다
각 문항에 대한 설명
Gini 불순도는 다음의 공식으로 계산됩니다 Gini 불순도 계산식 여기서 pi는 i번째 클래스의 비율(즉, 노드 내에서 i번째 클래스의 샘플 수 / 노드 내 전체 샘플 수)을 나타냅니다. 이 문제에서는 클래스 0인 레코드가 1개, 클래스 1인 레코드가 5개 있으므로, 각 클래스의 비율은 다음과 같습니다:
클래스 0: 1 / (1 + 5) = 1/6 클래스 1: 5 / (1 + 5) = 5/6
따라서, 이 노드의 Gini 불순도는 다음과 같이 계산됩니다: 따라서, 이 노드에 대한 불순도를 표현하는 Gini 값으로 가장 적절한 것은 ② 0.278 입니다. 이는 의사결정트리에서 노드의 불순도를 측정하는 Gini 값에 대한 정확한 이해를 바탕으로 한 선택입니다.
다음 시간에는 데이터베이스 기출문제 풀이 71-75번까지 풀이를 진행해 보겠습니다. 읽어 주셔서 감사합니다.