728x90
2024년 청룡의 해가 밝았습니다.
새해 복 많이 받으세요~!!

최근 4박 5일 동안 일본 여행을 급하게 떠나는 바람에 기출문제 풀이를 계속 이어서 진행하지 못해 죄송합니다.
오늘부터 다시 진행하고자 합니다.
2022년 제 23회 정보시스템 감리사 기출문제 풀이 96-100번까지 이어서 풀이를 진행하고자 합니다.
2024년에도 도움이 되시기를 바랍니다.
시스템 구조
문제 96
96. 다음 중 시계열 데이터를 예측하는데 주로 사용되는 딥러닝 모델로서 시간 t에서의 은닉층 (hidden layer) 출력값이 시간 t+1에서의 은닉층 입력값으로 사용되는 특징을 가진 것으로 가장 적절한 것은?
① 로지스틱회귀(logistic regression)
② 순환신경망(recurrent neural network)
③ 퍼셉트론(perceptron)
④ 합성곱신경망(convolutional neural network)
출제의도
딥러닝 모델 중에서 시계열 데이터를 예측하는데 가장 적합한 모델을 찾는 것인데, 시간 t에서의 은닉층 출력값이 시간 t+1에서의 은닉층 입력값으로 사용되는 특징을 가진 모델을 찾아야 합니다.
각 선택지에 대한 설명
① 로지스틱회귀(logistic regression):
로지스틱 회귀는 분류 문제를 해결하는 데 주로 사용되는 통계 기법입니다. 이는 시계열 데이터를 처리하는 데 일반적으로 사용되지 않습니다.
② 순환신경망(recurrent neural network):
순환신경망(RNN)은 시계열 데이터를 처리하는 데 가장 적합한 딥러닝 모델입니다. RNN은 이전 시간 단계의 정보를 현재 시간 단계로 전달하는 메커니즘을 가지고 있습니다. 따라서 시간 t에서의 은닉층 출력값이 시간 t+1에서의 은닉층 입력값으로 사용됩니다.
③ 퍼셉트론(perceptron):
퍼셉트론은 가장 간단한 형태의 인공신경망으로, 선형 분류 문제를 해결하는 데 사용됩니다. 이는 시계열 데이터를 처리하는 데 일반적으로 사용되지 않습니다.
④ 합성곱신경망(convolutional neural network):
합성곱신경망(CNN)은 이미지 분류, 객체 감지 등의 비전 관련 문제를 해결하는 데 주로 사용됩니다. 이는 시계열 데이터를 처리하는 데 일반적으로 사용되지 않습니다.
따라서, 이 질문의 정답은 ② 순환신경망(recurrent neural network)입니다.
문제 97
97. 정보시스템 하드웨어 규모산정 지침(정보통신단체 표준, TTAK.KO-10.0292, 2018.12.19.)에서 CPU의 규모를 산정할 때 OLTP와 WEB/WAS 서버 모두에서 고려하는 공통 항목으로 가장 적절하지 않은 것은?
① 사용자당 오퍼레이션 수
② 시스템 목표 활용률
③ 클러스터 보정
④ 피크타임 부하 보정
출제의도
정보시스템 하드웨어 규모산정 지침에 대해서 알고 있어야 합니다. 아래 내용을 참고하시기 바랍니다.
정보시스템 감리사 빈출 토픽 - 하드웨어 규모 산정
시스템구조 빈출 토픽 중 하드웨어 규모 산정에 대해서 알아보도록 하겠습니다. OLTP와 WEB/WAS 서버의 하드웨어 규모 산정방식하드웨어 규모 산정은 아무래도 한국정보통신기술협회(Telecommunication
chatstory.tistory.com
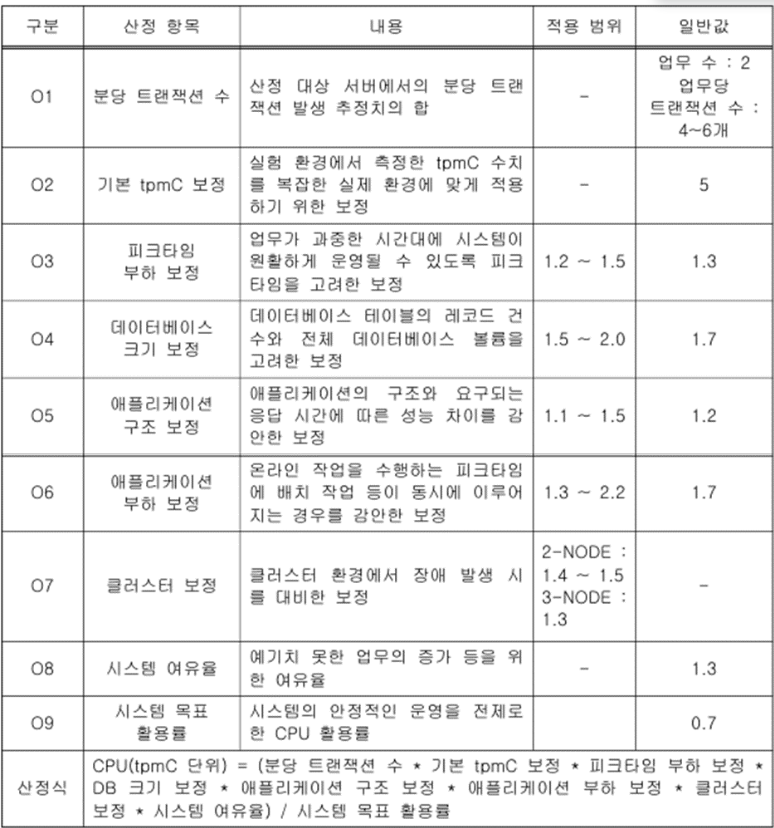
따라서, 정답은 ① 사용자당 오퍼레이션 수 입니다.
문제 98
98. 인-메모리 방식으로 연산을 수행하는 Spark에 관한 설명으로 가장 적절하지 않은 것은?
① 하둡2.0(YARN 환경)에서는 Spark를 지원하지 않는다.
② 맵리듀스 연산에 비해 그 계산 속도가 매우 빠르다,
③ 파이썬, 스칼라, 자바 언어를 사용하여 개발할 수 있다.
④ 기계학습, 그래프 연산 등 반복적인 계산 문제를 해결하는 데 적합하다.
출제의도
인 메모리 방식인 Spark 시스템에 대해서 알고 있어야 풀 수 있는 문제 이긴 하지만 해당 내용은 매우 간단한 이해만 있으면 되는 문제인 것 같습니다.
각 문항에 대한 설명
① 하둡2.0(YARN 환경)에서는 Spark를 지원하지 않는다:
이 설명은 잘못되었습니다. 실제로는 Spark는 YARN(Yet Another Resource Negotiator)을 포함한 하둡 클러스터에서 실행될 수 있습니다. YARN은 하둡2.0에서 도입된 클러스터 리소스 관리 시스템입니다.
② 맵리듀스 연산에 비해 그 계산 속도가 매우 빠르다:
이 설명은 맞습니다. Spark는 인-메모리 연산을 통해 맵리듀스 연산보다 훨씬 빠른 속도를 제공합니다.
③ 파이썬, 스칼라, 자바 언어를 사용하여 개발할 수 있다:
이설명은 맞습니다. Spark는 파이썬, 스칼라, 자바 등 다양한 언어를 지원합니다.
④ 기계학습, 그래프 연산 등 반복적인 계산 문제를 해결하는 데 적합하다:
이 설명은 맞습니다. Spark는 기계학습 라이브러리(MLlib)와 그래프 처리 라이브러리(GraphX)를 포함하고 있어, 반복적인 계산 문제를 효율적으로 처리할 수 있습니다.
따라서, 이 질문의 정답은 ① 하둡2.0(YARN 환경)에서는 Spark를 지원하지 않는다 입니다.
문제 99
99. 다음 중 DHCP(Dynamic Host Configuration Protocol) 프로토콜에서 사용하는 메시지에 대한 설명으로 가장 적절하지 않은 것은?
① DHCP ACK는 DHCP Request에 대한 응답으로 보낸다.
② DHCP Request는 클라이언트가 DHCP 서버에게 IP 주소를 요청한다.
③ DHCP Discover는 DHCP 서버가 IP 주소 할당 서버임을 알린다.
④ DHCP Offer는 DHCP 서버가 요청 클라이언트에게 할당할 IP주소를 제공한다.
출제의도
DHCP(Dynamic Host Configuration Protocol) 프로토콜에서 사용하는 메시지에 대한 이해를 테스트하는 것이고, DHCP는 네트워크에 연결된 장치들에게 동적으로 IP 주소를 할당하는 프로토콜입니다.
각 문항에 대한 설명
① DHCP ACK는 DHCP Request에 대한 응답으로 보낸다:
이 설명은 맞습니다. DHCP ACK(Acknowledgement) 메시지는 DHCP 서버가 클라이언트의 DHCP Request 메시지에 대한 응답으로 보내는 메시지입니다. 이 메시지는 클라이언트에게 IP 주소를 할당하거나 재할당하는 데 사용됩니다.
② DHCP Request는 클라이언트가 DHCP 서버에게 IP 주소를 요청한다:
이 설명은 맞습니다. DHCP Request 메시지는 클라이언트가 DHCP Offer 메시지를 받은 후, 해당 IP 주소를 사용하겠다는 의사를 DHCP 서버에게 알리는 데 사용됩니다.
③ DHCP Discover는 DHCP 서버가 IP 주소 할당 서버임을 알린다:
이 설명은 잘못되었습니다. DHCP Discover 메시지는 클라이언트가 네트워크 상의 DHCP 서버를 찾기 위해 보내는 메시지입니다. 이 메시지를 받은 DHCP 서버는 DHCP Offer 메시지를 클라이언트에게 보내서 IP 주소를 제안합니다.
④ DHCP Offer는 DHCP 서버가 요청 클라이언트에게 할당할 IP주소를 제공한다:
이 설명은 맞습니다. DHCP Offer 메시지는 DHCP 서버가 DHCP Discover 메시지를 받은 후, 클라이언트에게 IP 주소를 제안하는 데 사용됩니다.
따라서, 이 질문의 정답은 ③ DHCP Discover는 DHCP 서버가 IP 주소 할당 서버임을 알린다 입니다.
문제 100
100. 읽기 및 쓰기 성능이 각각 100,000 IOPS(Input /Output Operations Per Second)인 8개의 동일한 하드디스크로 RAID 10을 구성할 때 RAID 10의 읽기 성능과 쓰기 성능으로 가장 적절한 것은?
① 읽기: 400,000 IOPS, 쓰기: 400,000 IOPS
② 읽기: 400,000 IOPS, 쓰기: 800,000 IOPS
③ 읽기: 800,000 IOPS, 쓰기: 400,000 IOPS
④ 읽기: 800,000 IOPS, 쓰기: 800,000 IOPS
출제의도
RAID 10의 읽기 및 쓰기 성능에 대한 이해를 테스트하는 것으로 RAID 10은 RAID 1(미러링)과 RAID 0(스트라이핑) 의 조합으로 데이터의 안정성과 성능을 모두 고려한 구성입니다. 이 문제는 자주 출제되는 유형으로 잘 알고 있어야 합니다.
각 문항에 대한 설명
① 읽기: 400,000 IOPS, 쓰기: 400,000 IOPS:
RAID 10에서 읽기 성능은 모든 드라이브를 활용할 수 있으므로, 이 선택지는 읽기 성능을 낮게 평가하고 있습니다.
② 읽기: 400,000 IOPS, 쓰기: 800,000 IOPS:
이 선택지는 쓰기 성능을 과대평가하고 있습니다. RAID 10에서 쓰기 작업은 미러링 된 각 드라이브 쌍에 대해 동일한 데이터를 써야 하므로, 쓰기 성능은 개별 드라이브의 성능과 동일하게 유지됩니다.
③ 읽기: 800,000 IOPS, 쓰기: 400,000 IOPS:
이 선택지는 RAID 10의 읽기 및 쓰기 성능을 정확하게 반영하고 있습니다. 읽기는 모든 드라이브를 활용할 수 있으므로 성능이 증가하고, 쓰기는 미러링 때문에 개별 드라이브의 성능을 유지합니다.
④ 읽기: 800,000 IOPS, 쓰기: 800,000 IOPS: 이 선택지는 쓰기 성능을 과대평가하고 있습니다. RAID 10에서 쓰기 작업은 미러링 때문에 개별 드라이브의 성능을 유지합니다.
따라서, 이 질문의 정답은 ③ 읽기: 800,000 IOPS, 쓰기: 400,000 IOPS 입니다.
시스템 구조 기출문제 풀이를 모두 풀어보았습니다.
다음에는 보안 기출문제 풀이를 진해하도록 하겠습니다.
읽어주셔서 감사합니다.

반응형
LIST
'IT★자격증 > 정보시스템감리사 기출문제 풀이' 카테고리의 다른 글
| 2022년 제 23회 정보시스템 감리사 기출문제 풀이 - 보안(106-110) (102) | 2024.01.07 |
|---|---|
| 2022년 제 23회 정보시스템 감리사 기출문제 풀이 - 보안(101-105) (106) | 2024.01.06 |
| 2022년 제 23회 정보시스템 감리사 기출문제 풀이 - 시스템구조(91-95) (135) | 2023.12.25 |
| 2022년 제 23회 정보시스템 감리사 기출문제 풀이 - 시스템구조(86-90) (136) | 2023.12.24 |
| 2022년 제 23회 정보시스템 감리사 기출문제 풀이 - 시스템구조(81-85) (116) | 2023.12.23 |



