[오늘부터 데이터베이스 기출문제 51-55를 풀어보겠습니다.]
문제 51
| 51. ISO 8000의 데이터 품질 기준 관련하여 다음 괄호안에 적합한 용어는? ( ) 오류는 데이터가 표준 코드 값 또는 표준 도메인 값에 위배될 경우 발생한다. ① 충분성 ② 사실성 ③ 적합성 ④ 필수성 |
출제의도
ISO 8000의 데이터 품질 기준 중 하나인 '적합성’에 대한 이해를 검증하는 것입니다.
각 항목에 대한 설명은 다음과 같습니다:
① 충분성: 데이터가 특정 목적을 달성하기에 충분한 정보를 제공하는지를 나타냅니다.
예를 들어, 고객 데이터베이스에서 고객의 전체 이름, 연락처 정보, 주소 등이 모두 포함되어 있는지를 확인합니다.
② 사실성: 데이터가 현실 세계를 정확하게 반영하는지를 나타냅니다.
예를 들어, 제품 데이터베이스에서 제품의 가격, 사양, 재고 상태 등이 정확한지를 확인합니다.
③ 적합성: 데이터가 표준 코드 값 또는 표준 도메인 값에 맞는지를 나타냅니다.
예를 들어, 국가 코드가 ISO 3166-1 알파-2 표준에 따라 입력되었는지를 확인합니다.
④ 필수성: 데이터가 필수적으로 필요한 정보를 포함하고 있는지를 나타냅니다.
예를 들어, 직원 데이터베이스에서 직원의 고유 식별자, 이름, 직위 등 필수 정보가 모두 포함되어 있는지를 확인합니다.
따라서, 이 문제에서는 데이터가 표준 코드 값 또는 표준 도메인 값에 위배될 경우 발생하는 오류를 설명하고 있으므로, ③ 적합성이 가장 적절한 답변이 됩니다.
부연설명
ISO 8000은 데이터 품질에 대한 국제 표준입니다. 이 표준은 데이터의 품질을 평가하고 향상하기 위한 기준을 제공합니다.
ISO 8000의 데이터 품질 기준은 다음과 같은 주요 요소를 포함합니다:
- 정확성: 데이터가 현실 세계의 상태를 정확하게 반영하는지를 나타냅니다.예를 들어, 제품의 가격이나 사양이 정확한지, 고객의 연락처 정보가 최신인지 등을 확인합니다.
- 완전성: 데이터가 필요한 모든 정보를 포함하고 있는지를 나타냅니다. 예를 들어, 고객 데이터베이스에서 고객의 전체 이름, 연락처 정보, 주소 등이 모두 포함되어 있는지를 확인합니다.
- 일관성: 데이터가 시간과 공간에 걸쳐 일관되게 유지되는지를 나타냅니다. 예를 들어, 데이터베이스의 여러 부분에서 동일한 고객의 정보가 일관되게 표현되는지를 확인합니다.
- 적시성: 데이터가 필요한 시점에 사용 가능한지를 나타냅니다. 예를 들어, 재고 관리 시스템에서 실시간 재고 상태를 정확하게 반영하는지를 확인합니다.
- 적합성: 데이터가 표준 코드 값 또는 표준 도메인 값에 맞는지를 나타냅니다. 예를 들어, 국가 코드가 ISO 3166-1 알파-2 표준에 따라 입력되었는지를 확인합니다. 이러한 기준들은 데이터의 품질을 평가하고 향상하는 데 도움이 됩니다. 데이터 품질이 높을수록 데이터를 기반으로 한 의사결정의 정확성과 신뢰성이 향상됩니다.
따라서 ISO 8000은 데이터 중심의 조직에서 매우 중요한 역할을 합니다.
문제 52
| 52. 고정 길이 레코드 방식을 사용할 때, 레코드의 길이가 300 바이트, 블록의 크기가 4096 바이트, 블록 헤더의 길이가 12 바이트라고 가정한다. 다음 중 15개의 레코드를 저장하는 상황을 잘 표현한 것은? ① 첫 번째 블록에는 196 바이트가 남는다. ② 두 번째 블록에는 3,484 바이트가 남는다. ③ 두 번째 블록에는 3,494 바이트가 남는다. ④ 두 번째 블록에는 3,784 바이트가 남는다. |
출제의도
고정 길이 레코드 방식을 사용할 때 블록 내에 저장할 수 있는 레코드의 수와 남는 공간을 계산하는 능력을 검증하는 것입니다.
각 문항에 대한 설명과 계산은 다음과 같습니다:
먼저, 블록의 사용 가능한 크기를 계산해야 합니다. 블록 헤더의 길이를 블록의 전체 크기에서 빼면 됩니다.
즉, 4096 바이트(블록의 크기) - 12 바이트(블록 헤더의 길이) = 4084 바이트(블록의 사용 가능한 크기). 그런 다음, 이 사용 가능한 공간에 얼마나 많은 레코드를 저장할 수 있는지 계산합니다. 이를 위해 사용 가능한 공간을 레코드의 길이로 나눕니다.
즉, 4084 바이트(사용 가능한 공간) / 300 바이트(레코드의 길이) = 13.61. 이는 한 블록에 13개의 레코드를 저장할 수 있음을 의미하며, 소수점 이하를 버립니다.
따라서, 15개의 레코드를 저장하려면 두 개의 블록이 필요합니다.
첫 번째 블록에는 13개의 레코드가 저장되고, 두 번째 블록에는 나머지 2개의 레코드가 저장됩니다.
각 블록에서 남는 공간을 계산하려면 레코드의 총 길이를 사용 가능한 공간에서 빼면 됩니다.
첫 번째 블록에서는 4084 바이트 - 13 * 300 바이트 = 4084 바이트 - 3900 바이트 = 184 바이트가 남습니다.
두 번째 블록에서는 4084 바이트 - 2 * 300 바이트 = 4084 바이트 - 600 바이트 = 3484 바이트가 남습니다.
따라서, 올바른 답변은 ② 두 번째 블록에는 3,484 바이트가 남는다입니다.
문제 53
| 53. 다음 ERD(Entity Relationship Diagram)에서 수퍼키(superkey)에 해당되지 않는 것은? (단, Registration과 Vehicle_id는 각각 후보키이다.) |
 |
| ① (State, Year, Model) ② (Vehicle_id, Number) ③ (Registration, State) ④ (Registration, Vehicle_id, Year) |
출제의도
위 문제에 대해서 정리해서 다시 올리겠습니다.
정답은 ① (State, Year, Model) 입니다.
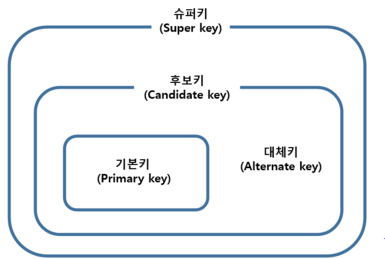
수퍼키는 유일성과 최소성을 모두 만족하는 속성들의 집합입니다.
- 유일성: 각 데이터 레코드에 대해 고유한 값을 가져야 합니다.
- 최소성: 수퍼키의 속성들을 제외하면 유일성을 만족하지 않아야 합니다.
각 문항에 대해서 설명드리겠습니다.:
① (State, Year, Model)
유일성을 만족하지만, 최소성을 만족하지 않습니다. State, Year 만으로도 유일성을 만족하기 때문입니다.
② (Vehicle_id, Number)
유일성과 최소성을 모두 만족하므로 수퍼키에 해당합니다.
③ (Registration, State)
애매합니다.
유일성을 만족하지만, 최소성을 만족하지 않기 때문에 수퍼키에 해당되지 않는거 같습니다.
하지만, 문제에서 (단, Registration과 Vehicle_id는 각각 후보키이다.) 라고 명시되어 있는데, (Registration, State)는 후보키의 부분집합이기 때문에 수퍼키에 해당하지 않습니다.
④ (Registration, Vehicle_id, Year)
유일성과 최소성 모두 만족하므로 수퍼키에 해당됩니다.
따라서, 정답은 ①과 ③인거 같은데... 답지에는 ①번인것 같습니다.
부연설명
문제 54
| 54. 릴레이션 R과 S에 대하여 |R| = 7, |S| = 6이다. 다음 릴레이션 연산결과의 상한값 중 가장 작은 값은? ① |R∪S| ② |R∩S| ③ |R-S| ④ |R×S| |
출제의도
릴레이션에 대한 기본적인 집합 연산을 이해하고, 각 연산의 결과로 나올 수 있는 튜플의 수를 추정하는 능력을 검증하는 것입니다.
각 항목에 대한 설명은 다음과 같습니다:
① |R∪S|: 릴레이션 R과 S의 합집합을 나타냅니다. 이 연산의 결과는 R과 S에 있는 모든 고유 튜플을 포함합니다. 따라서 결과의 상한 값은 |R|와 |S|의 합인 7 + 6 = 13이 될 수 있습니다.
② |R∩S|: 릴레이션 R과 S의 교집합을 나타냅니다. 이 연산의 결과는 R과 S에 모두 있는 튜플만을 포함합니다. 따라서 결과의 상한값은 |R|와 |S| 중 작은 값인 6이 될 수 있습니다.
③ |R-S|: 릴레이션 R에서 S를 뺀 차집합을 나타냅니다. 이 연산의 결과는 R에는 있지만 S에는 없는 튜플만을 포함합니다. 따라서 결과의 상한값은 |R|인 7이 될 수 있습니다.
④ |R×S|: 릴레이션 R과 S의 카테시안 곱을 나타냅니다. 이 연산의 결과는 R의 모든 튜플과 S의 모든 튜플의 조합을 포함합니다.
따라서 결과의 상한 값은 |R|와 |S|의 곱인 7 * 6 = 42가 됩니다.
따라서, 릴레이션 연산 결과의 상한값 중 가장 작은 값은 ② |R∩S|입니다.
문제 55
| 55. ER 모델의 약한 개체(weak entity)에 대한 설명 으로 옳지 않은 것은? ① 자기 자신의 키 속성을 가지지 않는 개체 타입을 약한 개체 타입이라고 한다. ② 약한 개체를 강한 개체와 연결시키는 관계 타입을 식별 관계라고 부른다. ③ 약한 개체가 식별 관계에 대해 전체 참여 제약을 가질 필요는 없다. ④ 모든 존재 종속(existence dependency)이 약한 개체 타입이 될 필요는 없다. |
출제의도
ER 모델에서 약한 개체(weak entity)에 대한 이해를 검증하는 것입니다.
각 항목에 대한 설명은 다음과 같습니다:
① 자기 자신의 키 속성을 가지지 않는 개체 타입을 약한 개체 타입이라고 한다.:
이 설명은 옳습니다. 약한 개체는 자체적으로 고유성을 확보할 수 없으며, 다른 개체와의 관계를 통해 식별됩니다.
② 약한 개체를 강한 개체와 연결시키는 관계 타입을 식별 관계라고 부른다.:
이 설명도 옳습니다. 식별 관계는 약한 개체를 강한 개체와 연결시키는 관계를 말하며, 이를 통해 약한 개체가 고유하게 식별됩니다.
③ 약한 개체가 식별 관계에 대해 전체 참여 제약을 가질 필요는 없다.:
이 설명은 옳지 않습니다. 약한 개체는 식별 관계에 대해 전체 참여 제약을 가집니다. 즉, 약한 개체의 모든 인스턴스는 반드시 식별 관계에 참여해야 합니다.
④ 모든 존재 종속(existence dependency)이 약한 개체 타입이 될 필요는 없다.:
이 설명은 옳습니다. 존재 종속은 개체가 다른 개체에 종속적인 상황을 나타내지만, 이는 반드시 약한 개체 타입이 되는 것은 아닙니다.
따라서, ER 모델의 약한 개체에 대한 설명으로 옳지 않은 것은 ③ 약한 개체가 식별 관계에 대해 전체 참여 제약을 가질 필요는 없다.입니다.
[다음 시간에는 데이터베이스 기출문제 56-60까지 풀어보도록 하겠습니다.]
'IT★자격증 > 정보시스템감리사 기출문제 풀이' 카테고리의 다른 글
| 2023년 제 24회 정보시스템 감리사 기출문제 풀이 - 데이터베이스(61-65) (15) | 2023.12.03 |
|---|---|
| 2023년 제 24회 정보시스템 감리사 기출문제 풀이 - 데이터베이스(56-60) (4) | 2023.12.02 |
| 2023년 제 24회 정보시스템 감리사 기출문제 풀이 - 소프트웨어공학(46-50) (3) | 2023.11.30 |
| 2023년 제 24회 정보시스템 감리사 기출문제 풀이 - 소프트웨어공학(41-45) (5) | 2023.11.29 |
| 2023년 제 24회 정보시스템 감리사 기출문제 풀이 - 소프트웨어공학(36-40) (3) | 2023.11.28 |



